Prerequisites
Before launching an RFT job, ensure you have:Dataset prepared and uploaded
Dataset prepared and uploaded
Your dataset must be in JSONL format with prompts (system and user messages). Each line represents one training example.Upload via CLI:Or via the Fireworks dashboard.
Evaluator created
Evaluator created
Your reward function must be tested and uploaded. For local evaluators, upload via pytest:The test automatically registers your evaluator with Fireworks. For remote evaluators, deploy your HTTP service first.
Fireworks API key configured
Fireworks API key configured
Set your API key as an environment variable:Or store it in a
.env file in your project directory.Base model selected
Base model selected
Choose a base model that supports fine-tuning. Popular options:
accounts/fireworks/models/llama-v3p1-8b-instruct- Good balance of quality and speedaccounts/fireworks/models/qwen3-0p6b- Fast training for experimentationaccounts/fireworks/models/llama-v3p1-70b-instruct- Best quality, slower training
Option A: CLI with Eval Protocol (Recommended)
The Eval Protocol CLI provides the fastest, most reproducible way to launch RFT jobs.Quick start
From your evaluator directory, run:- Uploads your evaluator code (if not already uploaded)
- Uploads your dataset (if
dataset.jsonlexists) - Creates and launches the RFT job
The CLI automatically detects your evaluator and dataset from the current directory. No need to specify IDs manually.
Step-by-step walkthrough
1
Install Eval Protocol CLI
2
Set up authentication
Configure your Fireworks API key:Or create a
.env file:3
Test your evaluator locally
Before training, verify your evaluator works:This runs your evaluator on test data and automatically registers it with Fireworks.
4
Create the RFT job
From your evaluator directory:The CLI will:
- Upload evaluator code (if changed)
- Upload dataset (if changed)
- Create the RFT job
- Display dashboard links for monitoring
5
Monitor training
Click the RFT Job link to watch training progress in real-time. See Monitor Training for details.
Common CLI options
Customize your RFT job with these flags: Model and output:Examples
Fast experimentation (small model, 1 epoch):Option B: Web UI
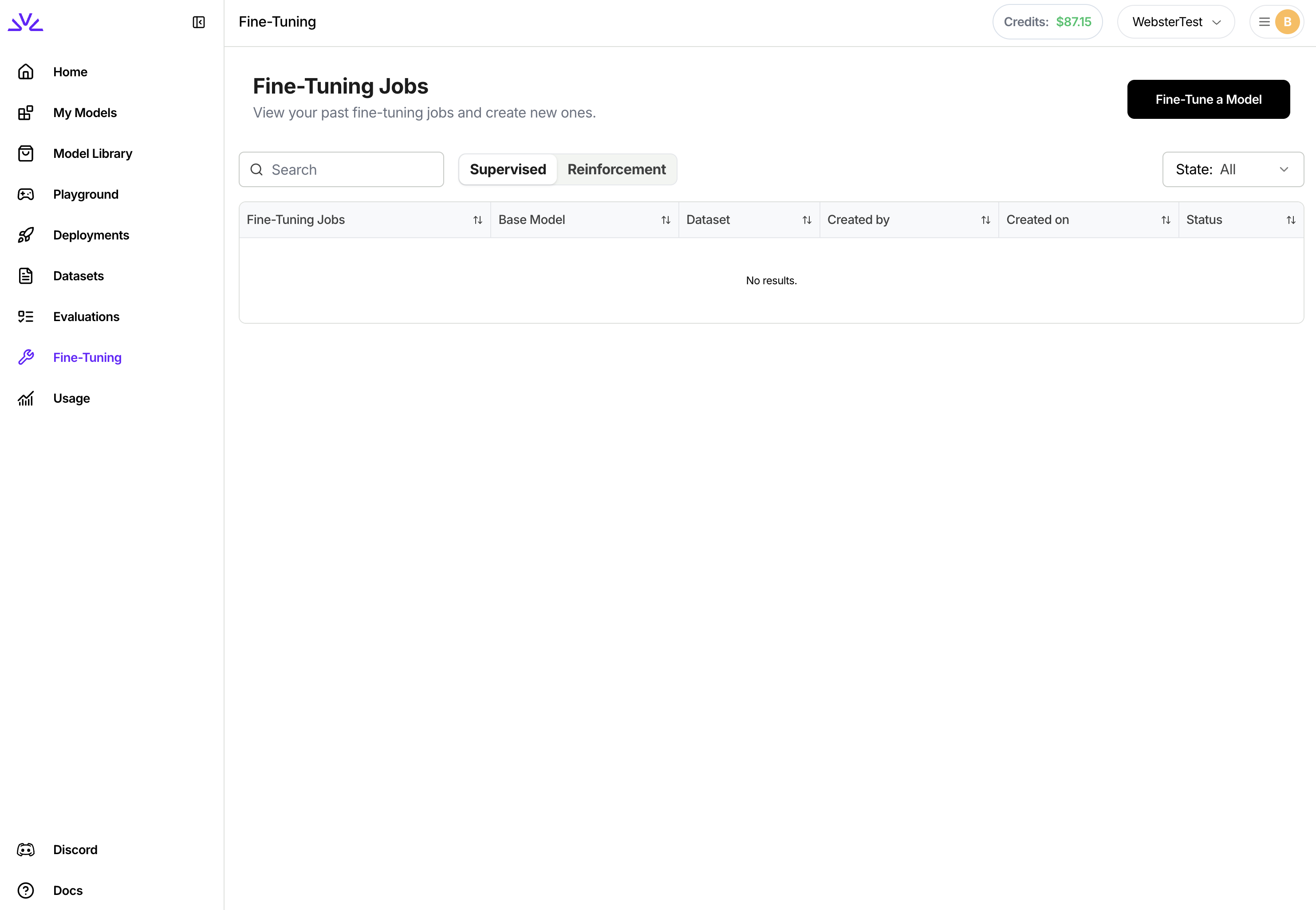
The Fireworks dashboard provides a visual interface for creating RFT jobs with guided parameter selection.1
Navigate to Fine-Tuning
- Go to Fireworks Dashboard
- Click Fine-Tuning in the left sidebar
- Click Fine-tune a Model
2
Select Reinforcement Fine-Tuning
- Choose Reinforcement as the tuning method
- Select your base model from the dropdown
Not sure which model to choose? Start with
llama-v3p1-8b-instruct for a good balance of quality and speed.3
Configure Dataset
- Upload new dataset or select existing from your account
- Preview dataset entries to verify format
- The UI validates your JSONL format automatically
messages array:4
Select Evaluator
- Choose from your uploaded evaluators
- Preview evaluator code and test results
- View recent evaluation metrics
For remote evaluators, you’ll enter your server URL in the environment configuration section.
5
Set Training Parameters
Configure how the model learns:Core parameters:
- Output model name: Custom name for your fine-tuned model
- Epochs: Number of passes through the dataset (start with 1)
- Learning rate: How fast the model updates (use default 1e-4)
- LoRA rank: Model capacity (8-16 for most tasks)
- Batch size: Training throughput (use default 32k tokens)
6
Configure Rollout Parameters
Control how the model generates responses during training:
- Temperature: Sampling randomness (0.7 for balanced exploration)
- Top-p: Probability mass cutoff (0.9-1.0)
- Top-k: Token candidate limit (40 is standard)
- Number of rollouts (n): Responses per prompt (4-8 recommended)
- Max tokens: Maximum response length (2048 default)
7
Review and Launch
- Review all settings in the summary panel
- See estimated training time and cost
- Click Start Fine-Tuning to launch
UI vs CLI comparison
| Feature | CLI (eval-protocol) | Web UI |
|---|---|---|
| Speed | Fast - single command | Slower - multiple steps |
| Automation | Easy to script and reproduce | Manual process |
| Parameter discovery | Need to know flag names | Guided with tooltips |
| Batch operations | Easy to launch multiple jobs | One at a time |
| Reproducibility | Excellent - save commands | Manual tracking needed |
| Best for | Experienced users, automation | First-time users, exploration |
Start with the UI to learn the options, then switch to CLI for faster iteration and automation.
Using firectl CLI (Alternative)
For users already familiar with Fireworks firectl, you can create RFT jobs directly:
eval-protocol:
- Requires fully qualified resource names (accounts/…)
- Must manually upload evaluators and datasets first
- More verbose but offers finer control
- Same underlying API as
eval-protocol
Job validation
Before starting training, Fireworks validates your configuration:Dataset format validation
Dataset format validation
- ✅ Valid JSONL format
- ✅ Each line has
messagesarray - ✅ Messages have
roleandcontentfields - ✅ File size within limits
- ❌ Missing fields → error with specific line numbers
- ❌ Invalid JSON → syntax error details
Evaluator validation
Evaluator validation
- ✅ Evaluator code syntax is valid
- ✅ Required dependencies are available
- ✅ Entry point function exists
- ✅ Test runs completed successfully
- ❌ Import errors → missing dependencies
- ❌ Syntax errors → code issues
Resource availability
Resource availability
- ✅ Sufficient GPU quota
- ✅ Base model supports fine-tuning
- ✅ Account has RFT permissions
- ❌ Insufficient quota → request increase
- ❌ Invalid model → choose different base model
Parameter validation
Parameter validation
- ✅ Parameters within valid ranges
- ✅ Compatible parameter combinations
- ❌ Invalid ranges → error with allowed values
- ❌ Conflicting options → resolution guidance
Common errors and fixes
Invalid dataset format
Invalid dataset format
Error:
Dataset validation failed: invalid JSON on line 42Fix:- Open your JSONL file
- Check line 42 for JSON syntax errors
- Common issues: missing quotes, trailing commas, unescaped characters
- Validate JSON at jsonlint.com
Missing required field 'messages'Fix: Each dataset row must have a messages array:Evaluator not found
Evaluator not found
Error:
Evaluator 'my-evaluator' not found in accountFix:- Upload your evaluator first:
- Or specify evaluator ID if using UI:
- Check Evaluators dashboard
- Copy exact evaluator ID
Insufficient quota
Insufficient quota
Error:
Insufficient GPU quota for this jobFix:- Check your current quota at Account Settings
- Request a quota increase through the dashboard
- Or choose a smaller base model to reduce GPU requirements
Parameter out of range
Parameter out of range
Error: See Parameter Reference for all valid ranges.
Learning rate 1e-2 outside valid range [1e-5, 5e-4]Fix: Adjust the parameter to be within the allowed range:Evaluator build timeout
Evaluator build timeout
Error:
Evaluator build timed out after 10 minutesFix:- Check build logs in Evaluators dashboard
- Common issues:
- Large dependencies taking too long to install
- Network issues downloading packages
- Syntax errors in requirements.txt
- Wait for build to complete, then run
create rftagain - Consider splitting large dependencies or using lighter alternatives
What happens after launching
Once your job is created, here’s what happens:1
Job queued
Your job enters the queue and waits for available GPU resources. Queue time depends on current demand.Status:
PENDING2
Dataset validation
Fireworks validates your dataset to ensure it meets format requirements and quality standards. This typically takes 1-2 minutes.Status:
VALIDATING3
Training starts
The system begins generating rollouts, evaluating them, and updating model weights. You’ll see:
- Rollout generation and evaluation
- Reward curves updating in real-time
- Training loss decreasing
RUNNING4
Monitor progress
Track training via the dashboard. See Monitor Training for details on interpreting metrics and debugging issues.Status:
RUNNING → COMPLETED5
Job completes
When training finishes, your fine-tuned model is ready for deployment.Status:
COMPLETEDNext: Deploy your model for inference.Advanced configuration
Weights & Biases integration
Weights & Biases integration
Track training metrics in W&B for deeper analysis:Set
WANDB_API_KEY in your environment first.Custom checkpoint frequency
Custom checkpoint frequency
Save intermediate checkpoints during training:Available in
firectl only.Multi-GPU acceleration
Multi-GPU acceleration
Speed up training with multiple GPUs:Recommended for large models (70B+).
Custom timeout
Custom timeout
For evaluators that need more time:Default is 60 seconds. Increase for complex evaluations.