Methods
Supervised Fine Tuning - Text
Train text models with labeled examples of desired outputs
Supervised Fine Tuning - Vision
Train vision-language models with image and text pairs
Direct Preference Optimization
Align models with human preferences using pairwise comparisons
Reinforcement Fine Tuning
Train models using custom reward functions for complex reasoning tasks
Free Reinforcement Fine-Tuning
When creating a Reinforcement Fine-Tuning job in the UI, look for the “Free tuning” filter in the model selection area: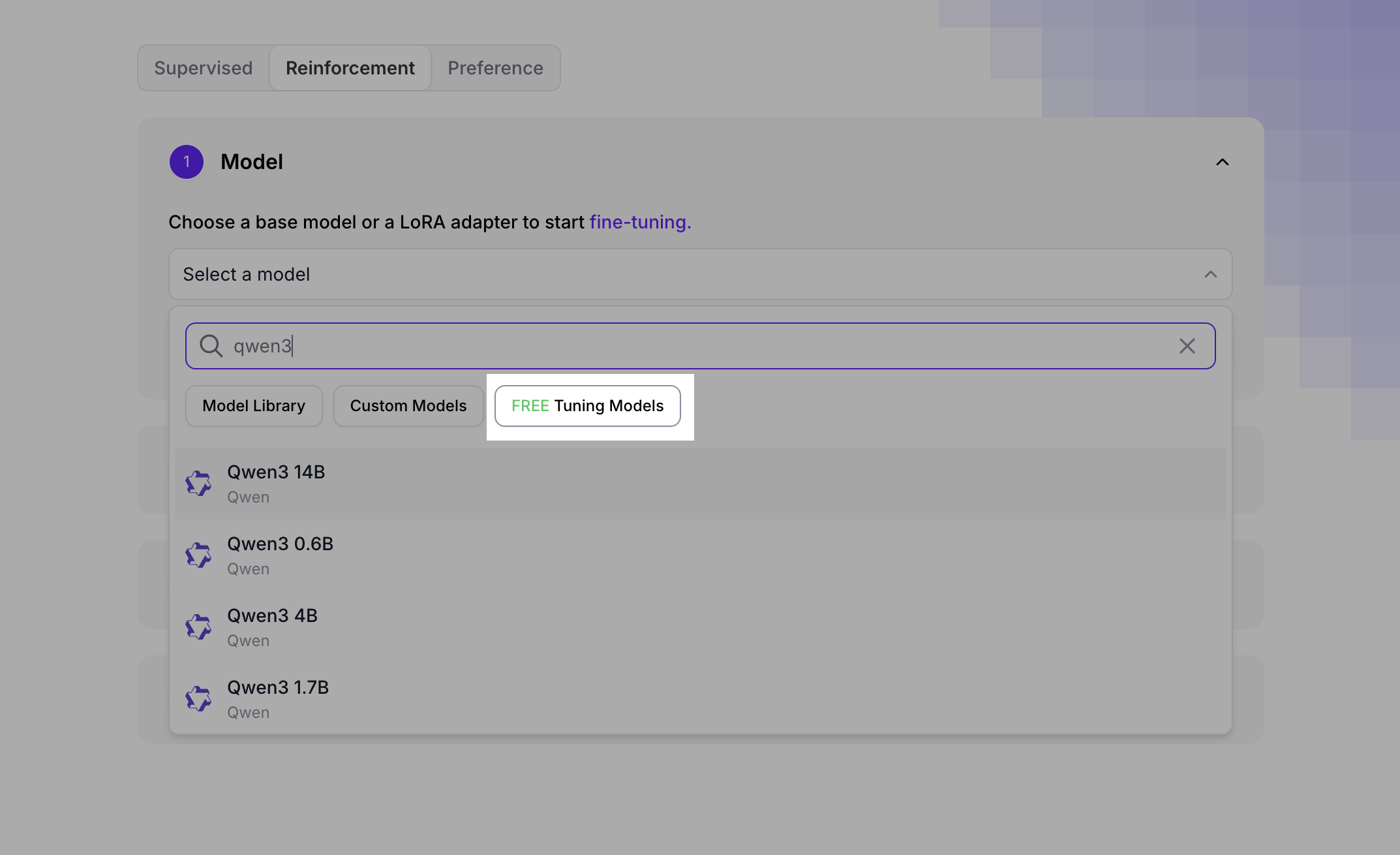
Supported base models
Fireworks supports fine-tuning for most major open source models, including DeepSeek, Qwen, Kimi, Gemma, GLM, and Llama families. The same set of base models is available for SFT, DPO, and RFT — once a base model is supported, every managed fine-tuning method works against it. Custom models uploaded by users are not automatically tunable. To use managed fine-tuning with an uploaded custom base model, the model must have a corresponding Hugging Face URL. Fireworks uses that URL to infer the training renderer and locate compatible training shapes. A custom model is supported only when Fireworks can resolve both a supported renderer and at least one compatible training shape. After the Hugging Face URL is set, tunability is refreshed by a background operation that runs about every 30 minutes, so the model may take up to 30 minutes to show asTunable: true. We are working to make this refresh faster.
The table below is generated from the live training shape registry. The “Max supported context length” is the largest max_supported_context_length across all training shapes registered for that base model — use it as the upper bound when you set a per-job context length on firectl sftj create, firectl dpoj create, or RFT job creation.
| Base model | Max supported context length |
|---|---|
gemma-4-26b-a4b-it | 256K (262,144 tokens) |
gemma-4-31b-it | 256K (262,144 tokens) |
glm-5p1 | 200K (200,000 tokens) |
kimi-k2p5 | 256K (262,144 tokens) |
kimi-k2p6 | 256K (262,144 tokens) |
llama-v3p3-70b-instruct | 128K (131,072 tokens) |
minimax-m2p5 | 192K (196,608 tokens) |
nemotron-nano-3-30b-a3b | 256K (262,144 tokens) |
qwen3-235b-a22b-instruct-2507 | 128K (128,000 tokens) |
qwen3-30b-a3b | 128K (131,072 tokens) |
qwen3-30b-a3b-instruct-2507 | 128K (128,000 tokens) |
qwen3-32b | 128K (131,072 tokens) |
qwen3-4b | 64K (65,536 tokens) |
qwen3-8b | 256K (256,000 tokens) |
qwen3-vl-8b-instruct | 256K (262,144 tokens) |
qwen3p5-27b | 256K (262,144 tokens) |
qwen3p5-35b-a3b | 256K (262,144 tokens) |
qwen3p5-397b-a17b | 256K (262,144 tokens) |
qwen3p5-9b | 256K (262,144 tokens) |
qwen3p6-27b | 256K (262,144 tokens) |